
Text to speech is everywhere. From Siri reading your messages to Google Maps giving you turn-by-turn directions. It’s in audiobooks, customer service bots, news readers, and even WordPress sites. But here’s the thing: most people have no idea how it actually works.
Is it just someone’s voice chopped into pieces? Is it fully AI-generated? What happens between typing a sentence and hearing it spoken aloud?
In this guide, you’ll get a full breakdown of how does text to speech work. We’ll walk through each step, show real-world examples, and introduce tools you can try for free, whether you’re a developer, educator, or content creator.
So, let’s get started!
What is text-to-speech?
Text to speech (TTS) is a tool that turns written text into spoken audio. You type something, and a voice reads it out loud. You’ll find it in phones, GPS apps, websites, and even smart home devices.
At its core, TTS takes the words you see on a screen and turns them into sound using a computer-generated voice. Some sound robotic, others sound almost human. It all depends on the tech behind it.
How Does Text to Speech Work (Step by Step)
Text to speech might seem simple on the surface. You type a sentence, press play, and hear a voice. But behind the scenes, there’s a lot going on.
Let’s break it down into a few clear steps so you can understand what’s really happening each time a device reads something out loud:
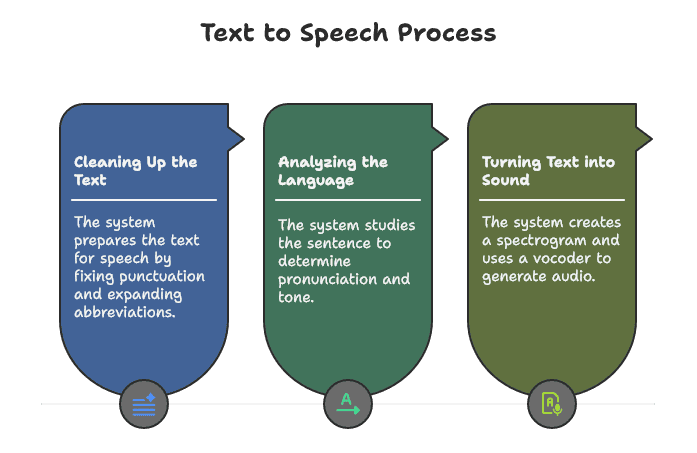
Step 1: Cleaning Up the Text
First, the system looks at the text and gets it ready for speech. It fixes punctuation, expands abbreviations, and figures out how to say numbers, dates, or symbols correctly. For example, if you write “$10”, the system knows to say “ten dollars” instead of “dollar ten.”
Step 2: Analyzing the Language
Next, the system studies the sentence. It figures out how each word is pronounced, how long to say it, and where to pause. This part also sets the tone, rhythm, and pitch. That’s what makes the speech sound more natural and less robotic.
Step 3: Turning Text into Sound
Once the system understands the words and how they should be spoken, it builds a visual map of the sounds. This is called a spectrogram. Then, a voice engine called a vocoder takes that map and creates the actual audio you hear.
Real-World Examples of TTS in Action
You’ve probably used text to speech accommodation without even thinking about it. It’s built into many tools and devices we use every day. Let’s look at a few places where TTS is making a real difference:
Accessibility
Text to speech was first created to help people with visual impairments or reading difficulties. Today, it’s still a key tool for accessibility.
Screen readers like VoiceOver (on Mac) or NVDA (on Windows) read everything out loud, making websites, documents, and apps easier to navigate for users who can’t rely on sight alone.
Education
TTS is often used in schools to support students with dyslexia or other reading challenges.
Tools like Read&Write or Bookshare let students listen to textbooks, articles, or assignments while following along with the text. This multisensory experience helps improve focus, comprehension, and confidence.
Virtual Assistants
If you’ve ever used Siri, Alexa, or Google Assistant, you’ve heard text to speech in action. These assistants combine TTS with speech recognition so they can listen to your commands and talk back in a natural realistic voice.
The smoother and more human the voice sounds, the better the overall experience.
Customer Service
Many companies now use TTS in their automated phone systems. When you call a support line and a voice presents you with menu options, that’s text to speech.
Some businesses also use AI chatbots that speak responses out loud, helping them handle more customers without adding staff.
Navigation and Smart Devices
TTS plays a big role in navigation apps like Google Maps or Waze. Instead of looking at your phone, you can keep your eyes on the road while the app reads out directions.
It’s also used in smart home devices, alarm clocks, and even appliances that need to talk to users.
Tools and Platforms for Text to Speech
Text to Speech (TTS) isn’t just for big tech platforms, there are tools for every type of user, from casual readers to developers and site owners.
Below are some of the best ways to try TTS on your own devices or integrate it into your workflow:
Built-In TTS (Free and Instant)
Most devices today come with built-in TTS features that require no downloads or setup. These are great for accessibility, quick listening, or basic screen reading.
- macOS: VoiceOver reads anything on the screen aloud with keyboard shortcuts.
- Windows: Narrator provides screen-reading support for apps and web pages.
- Android: Google’s TalkBack reads on-screen text and notifications.
- Chrome: The browser has built-in TTS functionality via extensions or ChromeVox.
Web-Based Tools
If you want a no-install, no-fuss solution, web-based TTS tools offer instant access.
- TTSReader: Copy-paste text and hear it read aloud instantly.
- Natural Readers: Offers both free and premium voices with browser access.
- IBM Watson TTS Demo: Try realistic voices powered by IBM’s AI directly in the browser.
WordPress Plugin: Text To Speech TTS
If you run a blog or WooCommerce store, the Text To Speech TTS plugin by AtlasAiDev is one of the most powerful and user-friendly options available.
- No registration or API keys required: Just install and the play button appears automatically on posts or pages.
- Multiple language: Supports 50+ languages and hundreds of browser-compatible voices.
- Customizable buttons: change colors, text, and playback settings to match your site’s style.
- Compatible with popular tools like WPML, Elementor, and WooCommerce.
- Advanced features in Pro: bulk MP3 generation, ChatGPT integration, Google Cloud TTS, custom CSS selectors, and even downloadable audio for users.
Developer APIs
For developers or teams building custom apps and experiences, these APIs offer the most control and flexibility:
- Google Cloud Text-to-Speech: Supports multiple languages and voices with SSML control.
- Amazon Polly: Real-time streaming and lifelike neural voices.
- IBM Watson TTS: AI-powered voice synthesis with language and tone control.
- ElevenLabs: High-quality voice cloning and emotional delivery, ideal for audiobooks and content creators.
Benefits and Limitations of Text to Speech
Text to speech has a lot going for it, but it’s not perfect. Here’s a quick look at what it does well and where it still needs improvement:
Benefits of TTS
- Makes digital content easier to listen to
- Helps users multitask while staying productive
- Improves engagement with written content
- Speeds up reading and comprehension time
- Supports dozens of languages and accents
- Reduces cost of hiring voice actors
- Easy to add to websites and apps
Limitations of TTS
- Some voices still sound robotic or flat
- Struggles to express tone or emotion
- Mispronounces names or technical terms
- Voice accents may not match expectations
- Can be misused for fake audio content
- Results vary across devices and browsers
Conclusion
To sum it up, text to speech has come a long way from its early robotic voices. Today, it’s powered by AI and neural networks that make speech sound more human and natural.
Behind every spoken word is a process that starts with text cleanup, runs through language analysis, and ends with audio generation using advanced models.
Whether you’re listening for convenience or relying on it for accessibility, TTS is quietly shaping how we consume content.
Understanding how does text to speech work gives you a clearer view of the technology that speaks for us in so many everyday moments.
FAQS
It breaks down the text, analyzes pronunciation and rhythm, then uses a voice model to generate audio.
Text processing, linguistic analysis, spectrogram generation, and a vocoder for speech output.
Yes. Most advanced systems use neural networks and deep learning.
TTS turns text into speech. ASR (Automatic Speech Recognition) does the opposite, speech to text.
🔊 Stay Updated with AtlasVoice
Get the latest tips on text-to-speech, accessibility, and WordPress delivered to your inbox.
No spam. Unsubscribe anytime.

