
When people visit your website, they often just scan the text. But when your content is read out loud with a voice, it can grab attention and keep visitors engaged.
That’s where text-to-speech comes in. It lets your site read content aloud using an automated voice. But many websites still use one default voice that sounds robotic and dull.
You can do better.
By using different text-to-speech voices, like a calm female tone, a warm male voice, or one with a clear accent, you make the experience more personal and human.
In this guide, you’ll learn how to add and use text to speech different voices on your website to improve how people listen and connect.
What is Text to Speech?
Text to speech, or TTS, is a tool that reads written content out loud using a computer-generated voice. Instead of your visitors reading your blog posts, product descriptions, or instructions, they can listen to them.
You’ve probably used TTS before, like when a map app gives you directions or when a screen reader reads a webpage aloud.
On websites, text to speech helps people who prefer listening, struggle with reading, or simply want to multitask. It also makes your content more accessible for users with visual impairments or learning differences.
TTS turns your written content into audio. And with the right setup, you can even choose which voice reads it out.
Why Use Different Voices on Your Website?
One voice doesn’t fit every visitor. Using text to speech with different voices makes your content easier to hear, understand, and enjoy. Here’s why that matters:
Make It More Accessible
If your audience speaks different languages or has hearing or reading challenges, one voice might not be enough. Some voices are hard to follow. Others feel too flat. Offering text to speech multiple voices makes your content easier to understand for more people.
Keep Visitors Engaged
People stay longer when the voice matches their style. Some prefer a soft tone. Others like something energetic. Giving them a choice makes the experience feel personal and keeps them listening.
Match Your Brand Voice
Your content has a tone. The voice should match it. A playful site needs a friendly voice. A serious site needs something steady and clear. Picking the right voice helps your brand sound the way it should.
How to Get Text to Speech Different Voices in WordPress
Getting different voices to read your content out loud on your site is easier than you might think. If you’re using the Text to Speech TTS plugin, here’s how to get different text to speech voices in just a few steps:
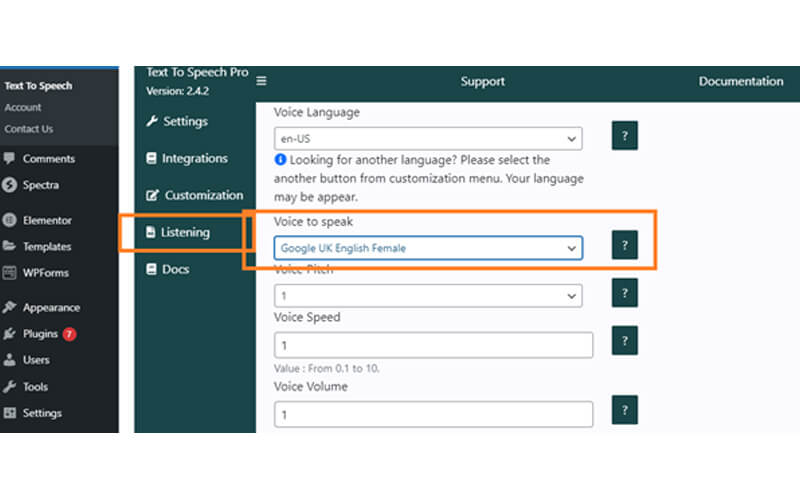
First, log in to your WordPress dashboard. If you’ve already installed the plugin, you’ll see a Text to Speech option in the left-hand menu.
Click on it, then go to the Listening tab. Inside that section, you’ll find a setting called Voice to Speak.
This is where you can choose the voice you want. You’ll see a list of options like male, female, accents, and more. Just pick the one that fits your content best and save the settings.
That’s it. Your website will now read content using the voice you selected.
Try 200+ realistic TTS voices with Text to Speech Pro – [Download Now]
Real-World Examples of Using TTS Voices
Here are a few examples to help you see how voice variety makes a real difference:
Education Sites Using Multiple Voices for Lessons
If you run an online course or a learning blog, you know how important it is to keep students focused. Some learners do better with a softer tone. Others respond more to a confident voice.
Using different TTS voices lets you match the teaching style to the topic or student age. This helps learners feel more connected to the material.
News or Blogs Offering Multilingual Reading Options
News sites and blogs often reach people from different parts of the world. By using text to speech voice accommodation with different accents or languages, you make your content easier to follow for more readers.
It also shows that you care about clarity and comfort for your audience.
Helping Visually Impaired or Blind Visitors
Many visually impaired users rely on audio to access your content. But if the voice sounds too fast, too flat, or hard to understand, they’ll leave.
Offering a range of voices calm, clear, and easy to listen to makes your site more usable and welcoming. It also shows you’re thinking about accessibility from the start.
Why Choose AtlasAiDev’s Text to Speech Plugin
If you’re looking for a powerful yet simple way to add text-to-speech to your site, Text To Speech Pro is the best choice. Here’s why:
Over 20 to 300+ Voice Options
Depending on the browser, you can access from over 20 to more than 300 voices. This allows you to choose text to speech different voices that fit your content’s tone and your audience’s language preferences with realistic voice text to speech.
No Registration or API Needed
The plugin works right after installation. You don’t need to sign up, create an account, or connect to any external API to start using it.
Multilingual and Customizable
You can select from 51+ supported languages, adjust the button’s color, size, and text, and control what content is read aloud using CSS selectors. You can even exclude certain tags, words, or sections from playback.
Supports WooCommerce and Custom Post Types
The plugin works with custom post types and integrates with popular tools like ACF, Custom Post Type UI, Toolset Types, and others. It also works with multilingual plugins like WPML, TranslatePress, and GTranslate.
Pro Features for More Control
With the Pro version, you can generate bulk MP3 files, use ChatGPT or Google Cloud TTS integration (optional), set up unlimited text aliases, and allow users to download audio files. You can also apply filters to customize content, exclude specific HTML tags, and add multiple audio players.
Built-in Compatibility with WordPress Tools
It supports popular plugins such as Elementor, WP-Optimize, LiteSpeed Cache, Autoptimize, and W3 Total Cache. This ensures smooth performance without conflicts.
FAQs
Install the Text to Speech Pro plugin on WordPress. Then go to the settings and choose your preferred voice under the “Voice to Speak” option.
Yes. The plugin includes high-quality voices that sound clear, natural, and human-like.
Absolutely. You can pick male or female voices and change them anytime from your WordPress dashboard.
Yes, Text to Speech TTS’s core version is free and includes over 20 voice options. Premium features are available for advanced needs.
No. The plugin is optimized for speed and doesn’t impact your SEO. Your written content remains visible to search engines.
Conclusion
Using text to speech different voices on your website isn’t just a nice extra. It makes your content easier to understand, more engaging, and more accessible for everyone who visits.
Whether you’re sharing blog posts, teaching online, or running a business site, giving your content a voice that fits your audience can leave a real impact.
And with Text to Speech TTS by AtlasAiDev, it takes just a few minutes to set up. No coding. No confusion. Just clear, natural voices your visitors will actually want to listen to.
So if you’re ready to bring your content to life with a realistic TTS voice generator, start by giving it the right voice. Try it today and hear the difference.
🔊 Stay Updated with AtlasVoice
Get the latest tips on text-to-speech, accessibility, and WordPress delivered to your inbox.
No spam. Unsubscribe anytime.

